HealthTech Company Builds Machine Learning Foundation with AWS Data Lake and Data Processing Pipeline
Challenge
A HealthTech firm needed to build efficient and maintainable data processing and machine learning pipelines to enable more complex data analytics work.
Solution
ClearScale set up a scalable data lake and used Amazon SageMaker as the central platform for the client’s machine learning operation.
Benefits
The company’s new data pipeline and architecture are more scalable and capable of handling larger volumes of analyses at a faster rate. A modern and scalable approach to building machine learning models was established.
AWS Services
Amazon SageMaker, AWS Step Functions, AWS Fargate, Amazon Aurora, Amazon S3
Executive Summary
A HaelthTech company recently worked with ClearScale on a large-scale data lake and data processing flow project. The project involved a machine learning Proof of Concept (POC) using Amazon SageMaker to unlock more advanced data analytics use cases in the future.
The Challenge
Previously, The HeathTech firm and ClearScale partnered on a data and analytics strategy assessment project. ClearScale provided a Migration Acceleration Program (MAP) assessment and created a data pipeline architecture. In this follow-up project, ClearScale was tasked with developing a scalable and maintainable machine learning pipeline to set the stage for more complex analytics work.
The customer’s existing process for analyzing data was already complicated. Going forward, the business would need an easy way for users to analyze its data samples effectively. This required a new intuitive web portal and streamlined deployment process. Any novel data points would need to integrate seamlessly into the existing data ecosystem and help optimize the client’s machine learning models.
ClearScale was responsible for making sure this end-to-end data processing flow was efficient, reliable, scalable, and accurate. Any errors or disruptions along the way would compromise data insights and prevent the company from making sound health recommendations.
The ClearScale Solution
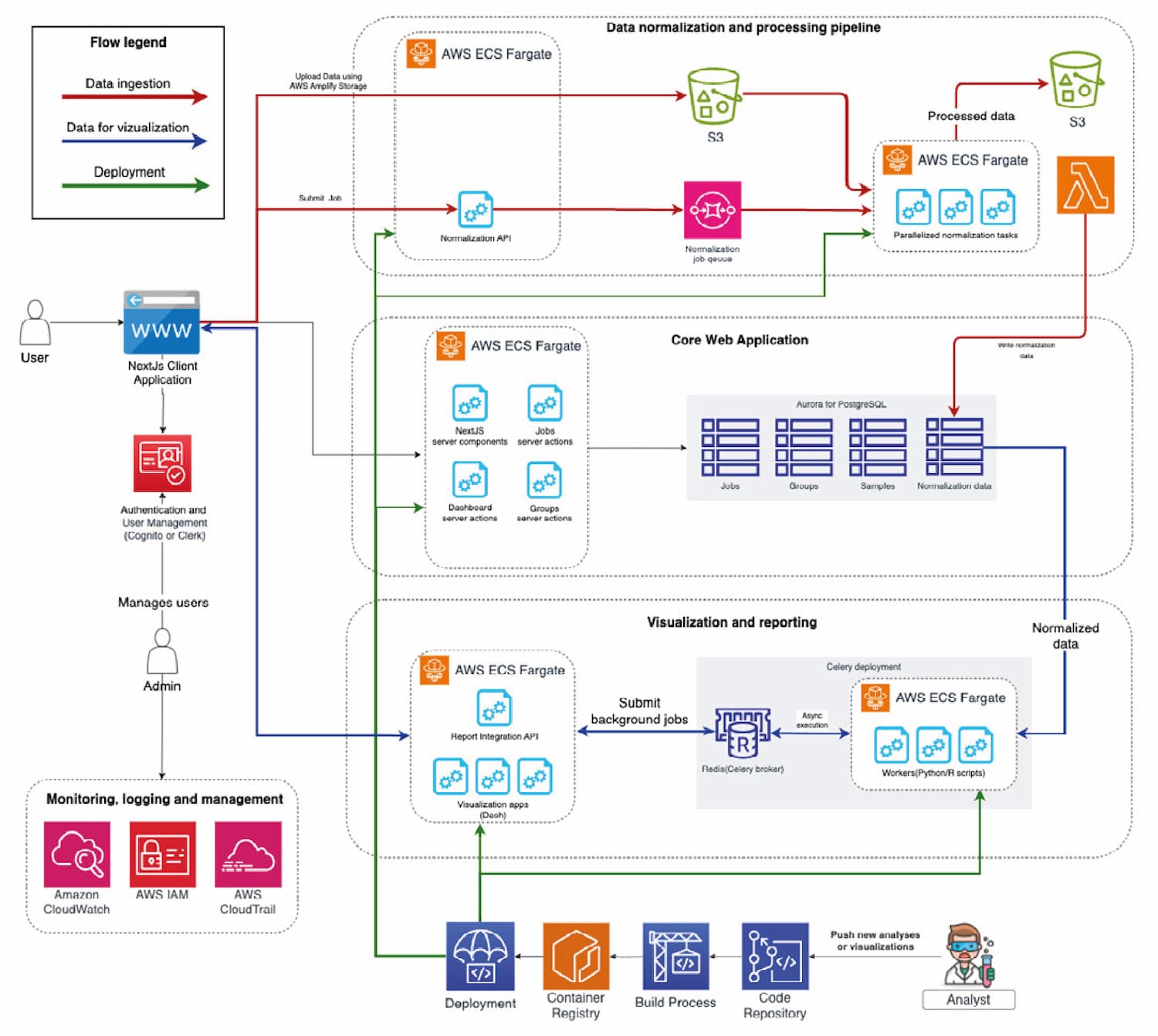
ClearScale’s engineers followed the latest best practices for data management and machine learning on the cloud. To ensure data processing scalability and maintainability, ClearScale deployed Docker images on AWS Fargate, a serverless compute engine for working with containers. The team used AWS Step Functions for orchestration and an Aurora for PostgreSQL database to store normalized data, jobs, groups, and samples. Additionally, ClearScale established a data lake on AWS that would serve as the primary source of data truth.
For the machine learning workflow, ClearScale relied on AWS SageMaker, AWS’ fully managed machine learning service. SageMaker provides a single integrated development environment that brings together all the tooling needed to build, train, and deploy machine learning models at scale. Companies can use notebooks, profilers, debuggers, and MLOps solutions directly within SageMaker. With this solution, the HealthTech company had a centralized framework for running and monitoring its ML processes.
On the web portal side, ClearScale used Next.js to write core web application functionality and Dash for data visualization. Any data uploaded by end users is handled by the web portal, and system administrators can monitor configurations, app performance, and access controls using Amazon CloudTrail, CloudWatch, and IAM.
Architecture Diagram
The Benefits
The combination of the web portal, previous data pipeline work, and new data processing flow has positioned the client to maintain its position as a market leader in its research space. Previously, the HealthTech firm had to conduct data analysis sequentially, resulting in processing times of several hours for every 100 samples. ClearScale’s redesigned solution reduced the 100-sample processing time to under one hour, freeing up significant capacity. The upgraded solution also helped mitigate errors in the deployment process by introducing code versioning and a better performing CI/CD pipeline.
Furthermore, before modernizing its data processing flow, the company had to scale its computational power manually to handle large sample batches. The client’s revised architecture on AWS now scales automatically based on batch size. The HealthTech provider’s resource consumption follows utilization more closely and can scale as needed to fulfill demand. These improvements mean it can increase analytical throughput, deliver better insights, and serve more customers overall.
Additionally, SageMaker was established as the central hub for the data science team, providing a unified platform for training and validating models, conducting experiments with ease, and advancing successful models to the next stage. This represents a significant advancement in data science capabilities.